Transform Disparate Engineering Data into Structured Knowledge
Ensure your maintenance strategies are well-informed with RDFox

As engineering companies move towards Industry 4.0, the question of how to leverage the vast amounts of knowledge that they currently store in non-uniform formats must be addressed.
In many organisations, critical information is scattered between excel spreadsheets and relational databases (RDBs), which require skilled IT experts to extract the knowledge. Unification of this data is critical for the creation of data-driven production systems and to ensure that maintenance strategies are created with all the relevant data.
One way to achieve this is with ontologies and semantic reasoning. This blog describes how to use RDFox, a triple store developed by Oxford Semantic Technologies, to extract and reason across data from disparate data sources (namely RDBs and CSVs).
This article was written by Caitlin Woods, a member of the System Health Lab Research Group at the University of Western Australia, in collaboration with Valerio Cocchi, a knowledge Engineer at Oxford Semantic Technologies.
The data
In this blog, we will use examples of data that are illustrative of those often found in engineering organisation - Failure Modes and Effects Analysis (FMEA) data and Work Order data.
FMEA is a widely used risk analysis process in engineering organisations. FMEA data is formulated in workshops involving multiple domain experts. This valuable data that informs an organisation's entire maintenance strategy is often locked away in spreadsheets (Hodkiewicz et. al, 2020).
The following table is an excerpt of a Failure Modes and Effects Analysis (FMEA) table, adapted from an international standard on Failure Modes and Effects Analysis (IEC60812, 2006).

Work order data is generated by technicians when they notice a problem with a piece of equipment. The work order data, is entered into a Computerised Maintenance Management System (CMMS) and then used to track work that needs to be performed on the equipment. For example:
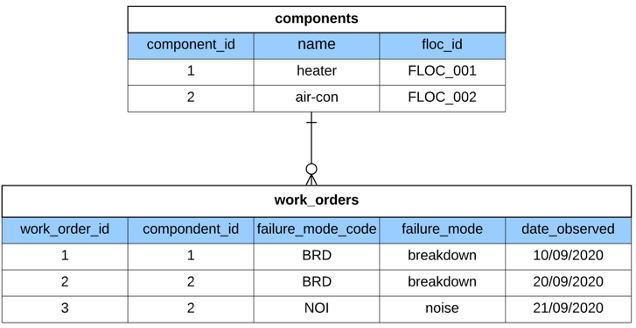
Observe that Failure Modes and their respective Failure Mode Codes (standardised in ISO14224:2016) are common across both data sources. We can query to see whether the failure modes that we expected (from our FMEA) are the same as the actual failure modes that are present in our work orders. The use case, ontological concepts and relationships that are used in this blog are adapted from a recent paper published in the ontology space (Lupp et al., 2020).
This blog will demonstrate how to do this using RDFox. If you're feeling adventurous you can follow along with RDFox. For the purpose of this tutorial, we created the FMEA spreadsheet as a CSV and created the work order database in Postgres.
Setting up RDFox
To begin, you need to download RDFox from http://www.oxfordsemantic.tech/downloads and request an evaluation licence from http://www.oxfordsemantic.tech/request-eval .
To get started quickly, we will set up a sandbox in RDFox that we can test our example in. After downloading RDFox, open up a terminal (command prompt if on windows). If you are unfamiliar with using the terminal, see here for instructions on how to navigate to a folder. Once you have navigated to the RDFox folder in the terminal, type the following:
./RDFox sandbox
dstore create maintenance par-complex-nn
active maintenance
endpoint start
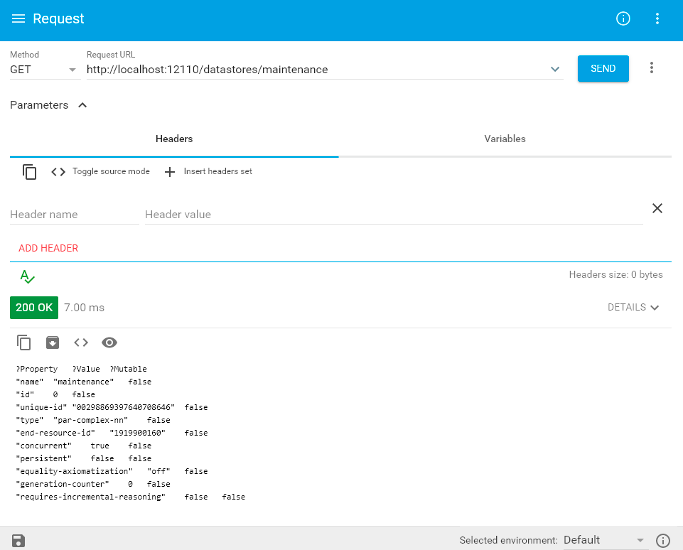
This should start a HTTP endpoint at http://localhost:12110 . For much of this example, we will be communicating with the RDFox triple store through this endpoint. To test that your endpoint is running, try sending a GET request to it. The request below will return the details of the new data store that we created in our sandbox (named "maintenance").
To send a request easily to an HTTP endpoint, you can use Advanced Rest Client or Postman.
Pull our FMEA and Work Order data into RDFox
Once we have got our sandbox created and started an endpoint, the next step is to collect information from our excel spreadsheet and our relational database and populate our triple store. In RDFox, we do this by creating data sources. We will need to create one data source for our excel spreadsheet and one data source for our relational database.
To register a data source for our csv file, we can send the following POST request to the endpoint that we created earlier.
http://localhost:12110/datastores/maintenance/datasources/FMEA-data?type=delimitedFile&file=<absolute_path_to_csv_file>&header=true
Note that the <absolute_path_to_csv_file> needs to be replaced with the actual path to the file on our computer. Also, out excel spreadsheet must be in a CSV format for this to work.
Similarly, to create a data source for our PostgreSQL relational database, we can send the following post request:
http://localhost:12110/datastores/maintenance/datasources/WorkOrder-data?type=PostgreSQL&connection-string=postgresql://<db_username>:<db_password>@<host>:<db_port>/<db_name>
Now we have created two data sources (named "FMEA-data" and "WorkOrder-data") it is time to "attach" our data sources to triples.
Creating Tupletables from Data Sources
We can attach our data sources in RDFox by storing the data in tupletables. We will need to create a tupletable for each table in our original data (the csv and the two tables in Postgres) whose data we would like to represent in our ontology. This can be done using the following three requests to our endpoint:
Add the component tupletable from Postgres
http://localhost:12110/datastores/maintenance/tupletables/http%3A%2F%2Fmaintenance.example%2Fdata%2Ftupletables%2Fcomponents?dataSourceName=WorkOrder-data&table.name=component&columns=3&1=http://maintenance.example/data/entities/component_{component_id}&1.datatype=iri&2={name}&3=http://maintenance.example/data/entities/{floc_id}&3.datatype=iri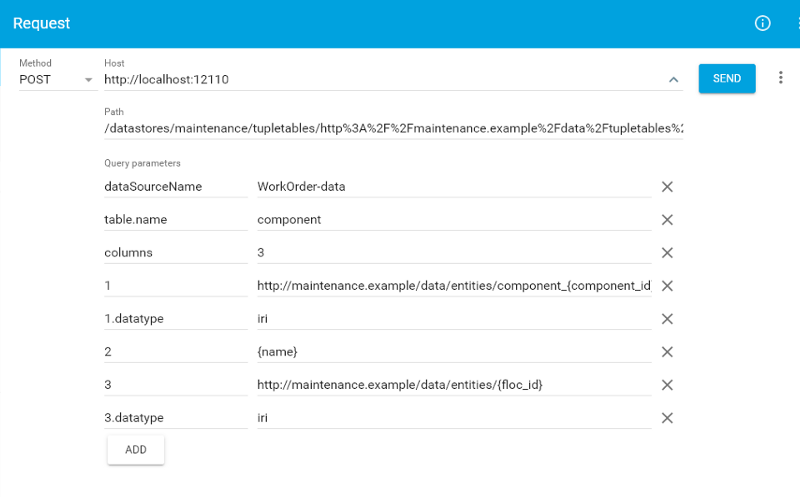
Add the work_orders tupletable from Postgres
http://localhost:12110/datastores/maintenance/tupletables/http%3A%2F%2Fmaintenance.example%2Fdata%2Ftupletables%2Fwork_orders?dataSourceName=WorkOrder-data&table.name=work_orders&columns=5&1=http://maintenance.example/data/entities/workOrder_{work_order_id}&1.datatype=iri&2=http://maintenance.example/data/entities/component_{component_id}&2.datatype=iri&3=http://maintenance.example/data/entities/failure_mode_{failure_mode}&3.datatype=iri&4=http://maintenance.example/data/entities/failure_mode_code_{failure_mode_code}&4.datatype=iri&5={date_observed}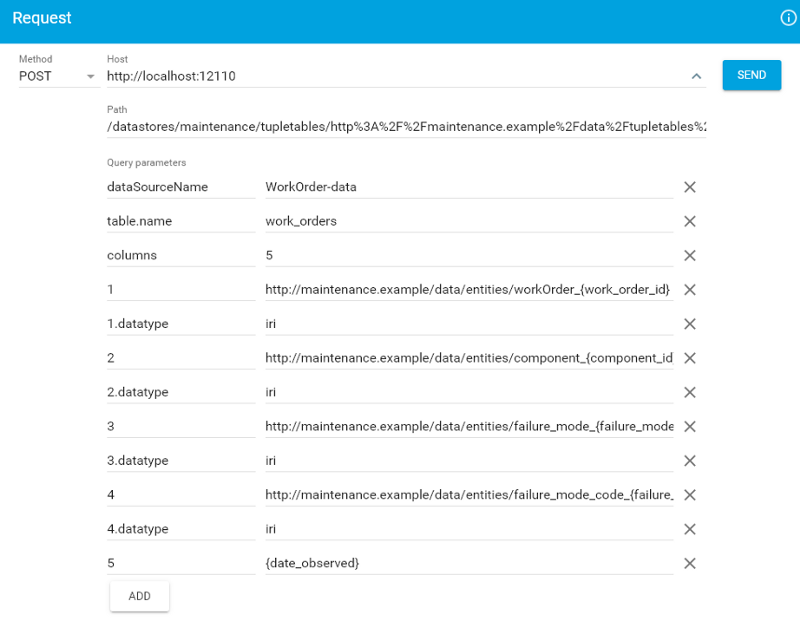
Add the FMEA tupletable from the csv
http://localhost:12110/datastores/maintenance/tupletables/http%3A%2F%2Fmaintenance.example%2Fdata%2Ftupletables%2Ffmea?dataSourceName=FMEA-data&columns=7&1=http://maintenance.example/data/entities/fmea_record_{1}_{5}&1.datatype=iri&2=http://maintenance.example/data/entities/{1}&2.datatype=iri&3={ComponentName}&4={Function}&5=http://maintenance.example/data/entities/failure_mode_{FailureMode}&5.datatype=iri&6=http://maintenance.example/data/entities/failure_mode_code_{FailureModeCode}&6.datatype=iri&7={FailureEffect}
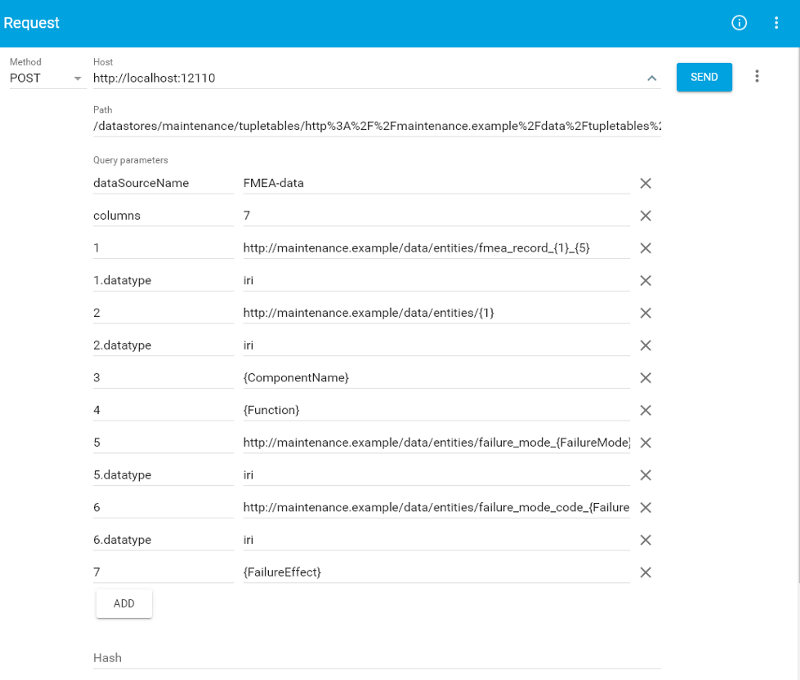
For more information on how these requests are constructed see the RDFox documentation on creating tupletables programmatically.

Mapping data into triples with rules
The final step before we can start querying our data is to map our data (now stored in tupletables) to concepts.
We can define concepts using rules. In RDFox, rules are generally created in a language called Datalog. However, we can also define concepts using the Web Ontology Language (OWL) and import the owl file to RDFox. In this example, we will use rules to define our concepts.
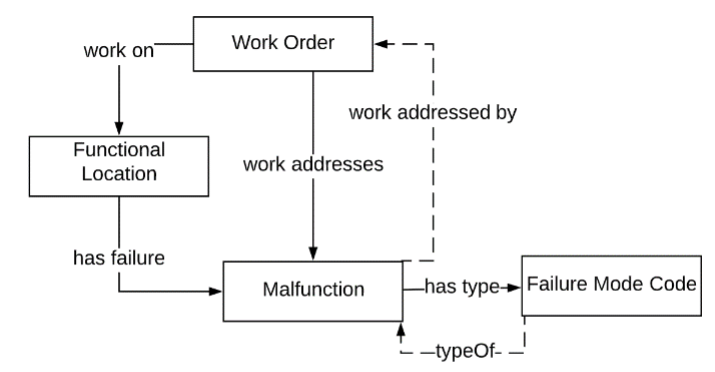
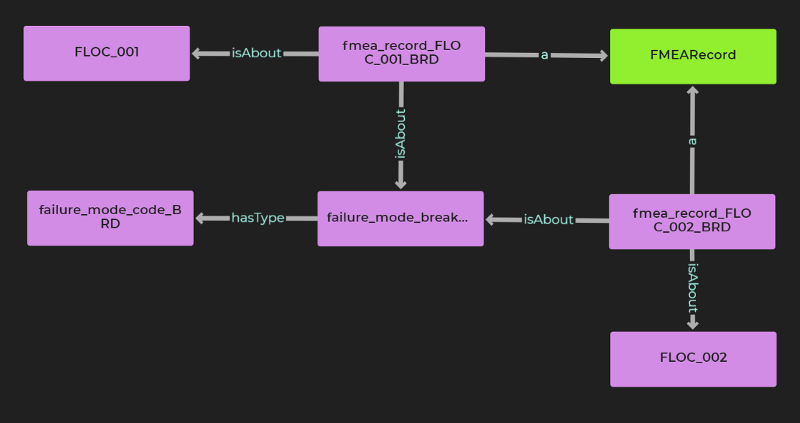
The image below is a conceptual model that we draw on in our rules (Lupp et al., 2020). In our rules the boxes represent concepts and the arrows represent relationships. The dotted lines in the diagram are known as inverse relationships. For example, if an instance of type Malfunction has type Failure Mode Code then our reasoner will also be able to infer the typeOf relationship.
To create our rules, we need to create four .dlog files with the following content:
File 1: mapComponents.dlog
@prefix type: <http://maintenance.example/data/classes/> .
@prefix prop: <http://maintenance.example/data/properties/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix tt: <http://maintenance.example/data/tupletables/> .
[?component, a, type:Component],
[?component, rdfs:label, ?componentName],
[?component, prop:hasFunctionalLocation, ?flocId],
[?flocId, a, type:FunctionalLocation]
:-
tt:components(?component,?componentName, ?flocId) .
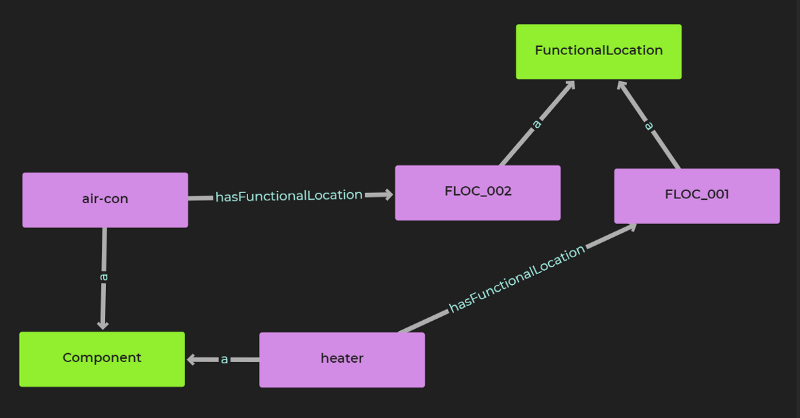
This rule looks at the 'components' tuple table that we have created in the previous section (mounted from Postgres). It tells us that the elements in the first column are of type 'component', they have a text 'label' (taken from the second column), and a 'functional location', taken from the third column.
File 2: mapWorkOrders.dlog
@prefix type: <http://maintenance.example/data/classes/> .
@prefix prop: <http://maintenance.example/data/properties/> .
@prefix tt: <http://maintenance.example/data/tupletables/> .
[?wo, a, type:WorkOrder],
[?wo, prop:workOn, ?component],
[?wo, prop:observedOn, ?date],
[?failureMode, a, type:FailureMode],
[?wo, prop:addresses, ?failureMode],
[?failureModeCode, a, type:FailureModeCode],
[?failureMode, prop:hasType, ?failureModeCode]
:-
tt:work_orders(?wo,?component,?failureMode,?failureModeCode,?date) .
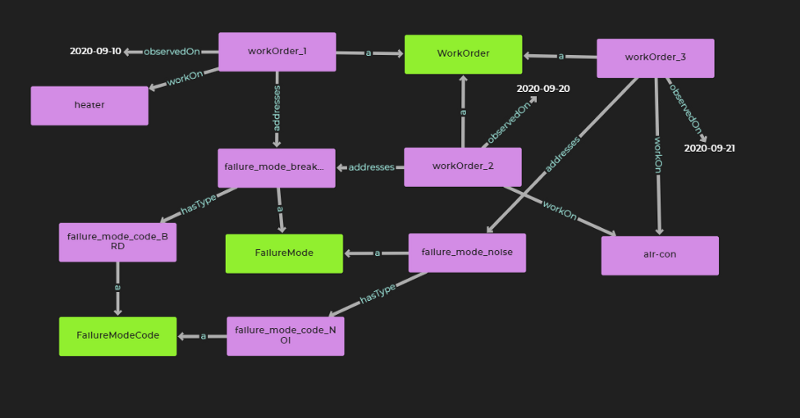
This rule looks at the work orders tuple table. Again, for each row, we take the entry in the first column and assert that it is of type 'work order'. Each work order describes a certain component that was maintained (2nd column), on a certain date (5th column). We also take the 'failure mode' observed in the work order (3rd column) and its standard failure mode code (4th column).
File 3: mapFMEA.dlog
@prefix type: <http://maintenance.example/data/classes/> .
@prefix prop: <http://maintenance.example/data/properties/> .
@prefix tt: <http://maintenance.example/data/tupletables/> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
[?fmeaRecord, a, type:FMEARecord],
[?fmeaRecord, prop:isAbout, ?functionalLocation],
[?fmeaRecord, prop:isAbout, ?failureMode],
[?failureMode, prop:hasType, ?failureModeCode]
:-
tt:fmea(?fmeaRecord, ?functionalLocation, ?componentName, ?function, ?failureMode, ?failureModeCode, ?failureEffect) .
This rule looks at the FMEA tuple table (mounted from the CSV). This table has 7 columns - 1 more than the csv –as the 1st and 5th entry of the CSV are composed to form a new entry, the 'fmea record'. This is necessary for disambiguation. That is, the same failure mode code, e.g. breakdown might result in "loss of cooling" or "loss of heating" depending on which component fails (i.e. heater or air conditioning). So, we create a new object, of class 'FMEARecord' as a concatenation of the functional location and failure mode code.
File 4: inverseRules.dlog
@prefix type: <http://maintenance.example/data/classes/> .
@prefix prop: <http://maintenance.example/data/properties/> .
@prefix tt: <http://maintenance.example/data/tupletables/> .
[?y, prop:typeOf, ?x]
:-
[?x, prop:hasType, ?y] .
[?y, prop:addressedBy, ?x]
:-
[?x, prop:addresses, ?y] .
The final rules are both contained in the inverseRules.dlog file. These rules do not look at the tupletables. Instead, they generate the inverse relationships (typeOf and addressedBy) that are present in the conceptual model (adapted from Lupp et al., 2020).
Once the .dlog files are created, we need to place them in the same directory where we started our sandbox. We then need to tell RDFox that these rules are to be used. To do this, we type the following into the terminal that we opened earlier:
import mapComponents.dlog mapWorkOrders.dlog mapFMEA.dlog inverseRules.dlog
Querying the data
Now that we have mapped our data from our different data sources to concepts, we can use SPARQL to query our data. These data sources were previously disparate and heterogenous; however, by querying the data we can demonstrate that the data sources are now integrated within RDFox. This will provide significant benefits for the engineering industry as it can provide engineers with all the relevant information needed to make decisions on maintenance strategies despite this data previously existing in non-uniform formats.
Some examples of useful queries are as follows:
Query 1: Get all Work Orders in the system
PREFIX type: <http://maintenance.example/data/classes/>
PREFIX prop: <http://maintenance.example/data/properties/>
PREFIX : <http://maintenance.example/data/entities/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?wo
WHERE {
?wo a type:WorkOrder.
}
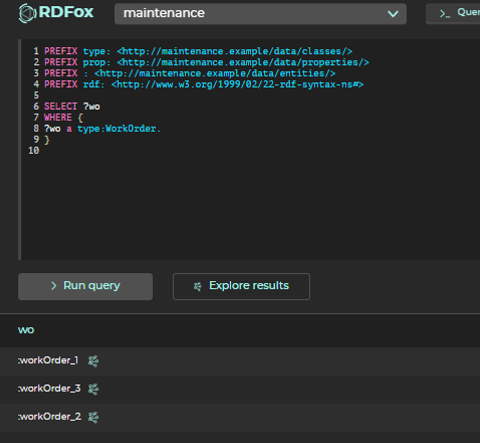
This query returns all individuals that are of type "WorkOrder". If you have been following along with us so far, you can click here to see this query run in the RDFox console.
Query 2: Get the "type of" Malfunction, given the Failure Mode Code "BRD".
PREFIX type: <http://maintenance.example/data/classes/>
PREFIX prop: <http://maintenance.example/data/properties/>
PREFIX : <http://maintenance.example/data/entities/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?malfunction
WHERE {
VALUES ?code {:failure_mode_code_BRD} #Set which code you want from here
?code prop:typeOf ?malfunction .
?malfunction a type:FailureMode;
}
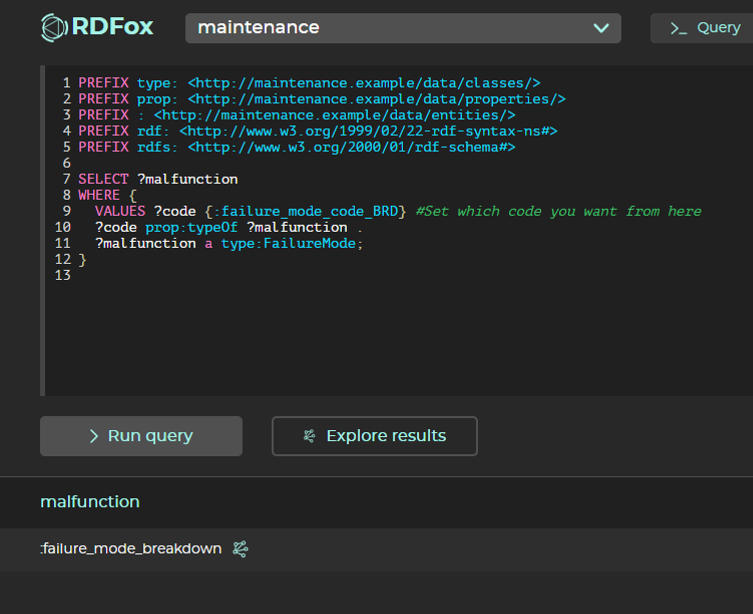
This query users the inverse relationship, "typeOf", to get all malfuctions that are related to the individual "failure_mode_code_BRD". Note that for the purpose of this example, we are using the terms "Failure Mode" and "Malfunction" synonymously. Click here to see this query in the console.
Query 3 (Demonstrates use case): Find all Failure Modes that we see in our work orders, but were not captured in our FMEA.
PREFIX type: <http://maintenance.example/data/classes/>
PREFIX prop: <http://maintenance.example/data/properties/>
PREFIX : <http://maintenance.example/data/entities/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
SELECT ?func_loc ?malfunction
WHERE {
?wo prop:workOn ?component ;
prop:addresses ?malfunction .
?component prop:hasFunctionalLocation ?func_loc .
?fmea_record prop:isAbout ?func_loc .
FILTER NOT EXISTS { #Here we make sure to take away the codes that appear in the FMEA csv
?fmea_record prop:isAbout ?malfunction .
}
}
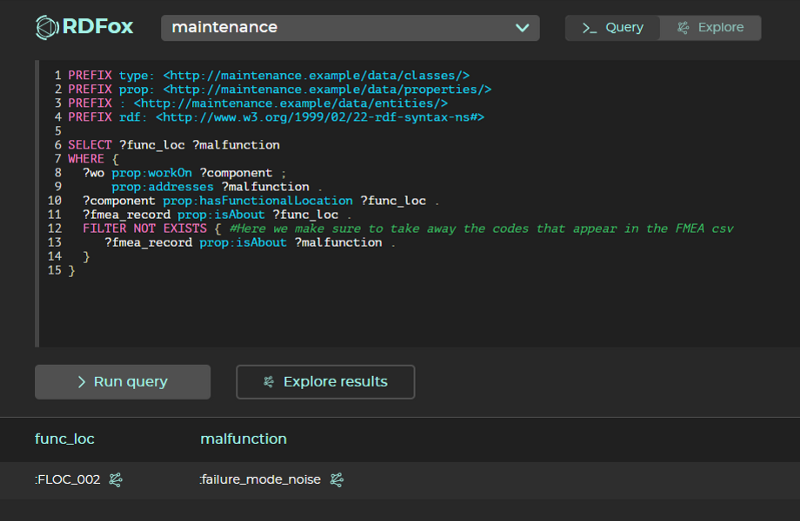
This query finds all malfunctions (or failure modes in this example) that exist our work order records. It then removes all malfunctions that are in the FMEA. What's left over is all malfunctions that are present in our work orders but not in our FMEA csv. Click here to see this query run in the console.
Informed maintenance strategies with RDFox
The engineering domain is considered to be at the forefront of innovation. However, while critical information is scattered between various excel spreadsheets or relational databases the full potential of engineering knowledge remains locked away. Maintenance strategies could be enhanced if these data sources are integrated. RDFox, a knowledge graph and semantic reasoning engine, is a solution to this problem.
By integrating FMEA and work order data, as shown in this article, and other data sources within the engineering domain, it will be easier to validate maintenance strategies. In Query 3, we determined that there was a missing failure mode in our FMEA that did appear in our work order data. From an engineer's perspective, this implies that there has been a failure that was not thought about in the maintenance strategy. Likely, the maintenance strategy might need to be updated so that the air conditioner component does not experience a failure involving excessive noise.
Note that the use of this technology in engineering and asset-owning organisations is not limited to this single use case. Widespread use of spreadsheets and existing legacy systems in these organisations means that it is common for data to be represented and interpreted in different ways. Ontologies provide a mechanism for consistent data representation and knowledge management within organisations.

Looking forward
Leveraging vast amounts of data to create actionable intelligence is a problem many industries face. This blog has demonstrated how critical, yet disparate, engineering data can be converted into triples and integrated within the RDFox triplestore, where it can be reasoned over and queried.
This type of application would be hugely beneficial to the engineering domain where large data silos and heterogeneous data formats contribute to a loss of efficiency or sub-optimal maintenance strategies. For engineers, innovation and efficiency are integral to their roles, thus moving to a more integrated approach for information management appears inevitable.
This article was produced in collaboration by Caitlin Woods from The System Health Lab and Valerio Cocchi from Oxford Semantic Technologies. This article will also be published on the blog site for Oxford Semantic Technologies.
References
Hodkiewicz, M., Klüwer, J. W., Woods, C., Smoker, T., & French, T. (2020). Digitalization and reasoning over engineering textual data stored in spreadsheet tables. IFAC-PapersOnLine, 53(3), 239–244.
IEC60812. (2006). IEC 60812: Analysis Techniques for System Reliability-Procedure for Failure Mode and Effects Analysis (FMEA).
ISO14224. (2016). 2016 Petroleum, petrochemical and natural gas industries - Collection and exchange of reliability and maintenance data for equipment.
Lupp, D. P., Hodkiewicz, M., & Skjæveland, M. G. (2020). Template Libraries for Industrial Asset Maintenance: A Methodology for Scalable and Maintainable Ontologies. In CEUR Workshop Proceedings (Vol. 2757, pp. 49–64)