Databases are everywhere. They come in all shapes (relational, graph, document-based) and sizes. Every time a new software application is created, it often comes with a brand new accompanying database. Along with this database, comes a whole new way of representing information. However, this information is often the same information that is already used in other software applications. To show why this is a problem, consider the following situation:
A manufacturing company wants to know how much they are spending on buying new parts for equipment each year. However, different workshops store information about their part replacements in a different way. Say, for example, data is represented by each workshop in a relational database. Workshop 1 has a database schema that looks like Figure 1 and Workshop 2 has a database that looks like Figure 2. Given that the representations are different, can the organization calculate the total cost of parts each year?
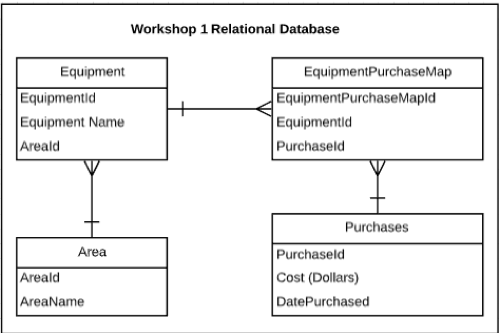
Figure 1: Workshop 1 Relational Database
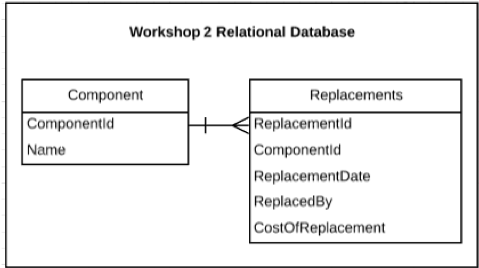
Figure 2: Workshop 2 Relational Database
The solution that most people will jump to is to perform a SQL query to extract the relevant data for both databases and perhaps use some code to join the data together and make a calculation. However, this requires someone to know exactly how the parts and cost data is represented each database. In reality, database schemas are far more complex than those shown in Figures (1) and (2). Only a specific few members of an organization will know the intricacies of how a particular database is laid out and be able to query it. This means that significant time and effort will be spent trying to ask this simple question of your data! Then if someone else wants to ask a similar question, they would have to do the whole exercise again.
Another solution to this problem is to use ontologies to create a generalized representation of your data. Each database can then be mapped to the ontology’s representation. Someone who then wishes to ask a question of your data, need only query the ontology. Figure 3 shows what this would look like. The best part about this idea is that it only needs to be set up once. If the word “ontology” is new to you, feel free look at our other blog on “How to explain ontologies to your boss” for a general description.
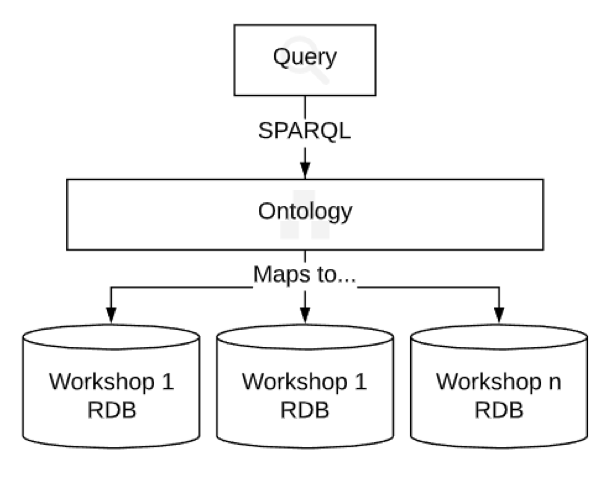 Figure 3: OBDA Concept
Figure 3: OBDA Concept
In practice, a technique that can be used to achieve the architecture Figure 3 is the OBDA (Ontology-based data access) paradigm. This paradigm was first explored in the mid-2000s. OBDA uses a technique called query rewriting. This means that it takes a query written for the ontology (in a query language called SPARQL) and uses pre-defined mappings to transform that query into SQL for your relational database. A popular tool to create OBDA systems is called Ontop. More about Ontop and the OBDA paradigm can found at their website: https://ontop-vkg.org/
Keep an eye on future blog posts for a full-worked example of the OBDA paradigm as well as some of its benefits and limitations.
I hope this blog was useful for you in your mission to start using ontologies in your organization. If you have questions, comments, or ideas about what I should write on next, please reach out to me at caitlin.woods@research.uwa.edu.au
Written by Caitlin Woods
Research Assistant at The UWA System Health Lab